When I set out to build a local Retrieval-Augmented Generation (RAG) pipeline, I knew I needed something lean, fast, and—dare I say—llama-approved. Because like… who doesn’t like llamas. Enter Larry Llama, my alliterative sidekick which is a front for my orchestration of local AI tools powered by bare-metal Ollama, containerized n8n, Qdrant, and Apache Tika (at the time of writing). Here, I’ll quickly take you through the ups, downs, and caffeine-fueled middle sections of spinning up a fully local RAG system in a weekend.
Why “Larry Llama”?
Naming things is hard. Larry Llama reflects two core ideals:
- Alliteration because everyone should.
- Local-first: Ollama runs on my machine bare metal for GPU access, while docker handles the other services
Why Local AI?
At my core, I just like learning new things.
It started because I wanted to use cool open source models. I had to upgrade my hardware from my tiny 8gb MBP, then learn Ollama, and all the recent changes in the LLM space. Like “wtf is quantization?” is a perfectly reasonable question that I now know the answer to (at least in a very abstract sense).
But then I learned the power of n8n and had to update my own knowledge of docker. Side projects like this are how I’ve taught myself a working knowledge of a variety of areas in the development process while being able to sharpen my expertise in others.
So what are we working with?
Tech Stack Overview (as of today)
- Ollama (bare-metal): Local LLM inference—no vendor lock-in, no model tie downs.
- n8n (Docker): Visual workflows for both ingesting documents and managing chat interactions.
- Qdrant (Docker): Vector store tuned for lightning-fast nearest-neighbor searches.
- Apache Tika (Docker): Rock-solid text and metadata extraction from any document format.
- File-system monitoring (via n8n)
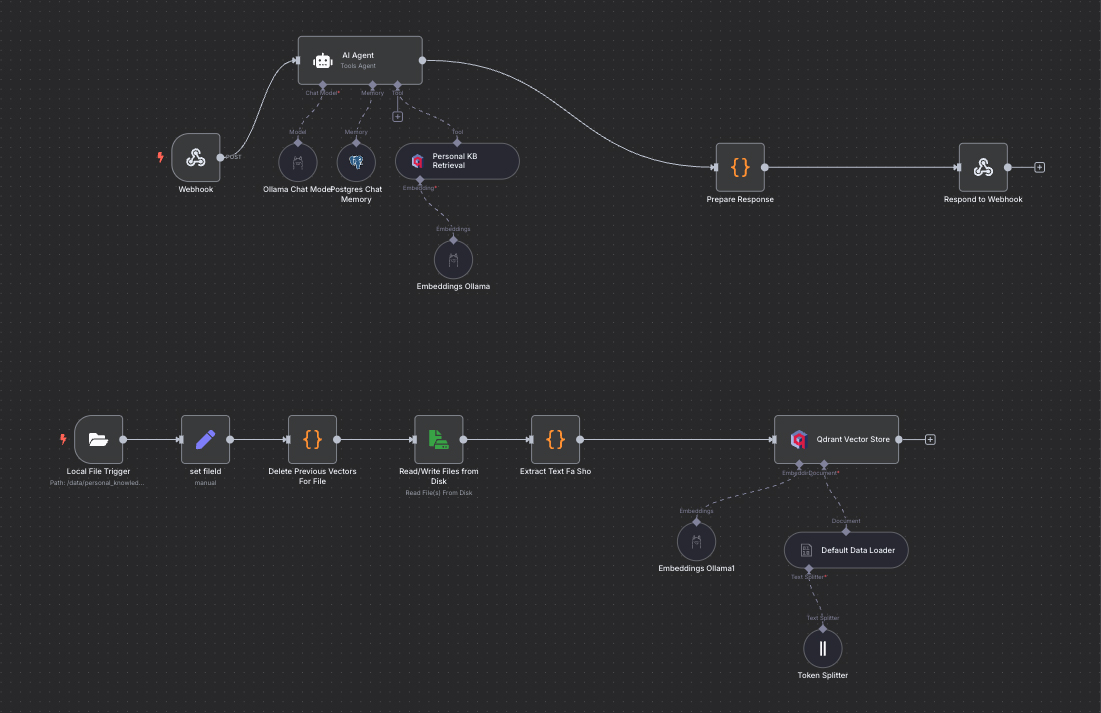
Containerized Ingestion Pipeline From Local Files
Thanks to modern tooling… (though I had to re-remember docker and then learn how it changed from when I used it three years ago), Docker got me going quick. Compose files are truly goated.
docker-compose up -dNo real deep dives into container internals required for these—Tika, Qdrant, and n8n all “just worked”. Insofar as I only needed a brief google of Qdrant’s query syntax and had actually… never met Apache Tika before in my life. But after a bit (a lot) of trial and error, I had an ingestion pipeline set up in n8n and humming away vectorizing documents (whatever absolute wizardry that is).
- Local File Trigger: Watch ./knowledge_base/ for new or changed files. (which is linked in the compose file to my local knowledge base of markdown files).
- Tika Extraction: Spin up Tika container, extract text and metadata.
- Embed with Ollama: Send chunks to Ollama’s embedding API.
- Upsert to Qdrant: Store vectors under the file’s path for query later.
I was pleasantly surprised that docker networking isn’t nearly as terrible as it was when docker first existed. Heavens. I’m sure my thinning hair has got to be at least partially attributable to that.
Anyway.
Chat workflow
Once our ingestion workflow was locked in, building the chat path felt almost ceremonious:
- Webhook: Receive user prompt from Open-WebUI.
- Conversation Memory: Retrieve past turns from our Postgres container.
- Vector Retrieval: Query Qdrant for top-k relevant docs.
- LLM Response: Feed context + prompt into Larry Llama on Ollama.
- Prepare & Respond: Format and send back response via n8n webhook.
The future of this system
If you’ve used n8n before, as I’m learning, you understand that the sky is really the limit for automation. It’s truly an excellent tool. I’m hoping to integrate crawling as Cole Medin did in some of his other work (mentioned below) and a way to route that directly into my ingestion workflow as well. Along with some other tools to streamline my daily work.
The work in action
A brief quick shout-out to Cole Medin
None of this would’ve clicked so quickly without Cole Medin’s work and YouTube channel. If you’re building local AI pipelines, do yourself a favor and binge his tutorials.
I’ll try and keep this blog updated as this workflow changes, but the current state of it is available (at least sort of) here.
Thank you for your kind attention.